
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- apitestcase
- Continuous Deployment
- DjangoCache
- 도커
- Transaction
- racecondition
- database
- CI
- Python
- testcase
- Prefetch_related
- Continuous Delivery
- aws
- aggregate
- 코루틴
- 백준
- QuerySet
- F객체
- Git
- django
- DjangoRestFramework
- to_attr
- DRF
- CD
- docker
- dry-yasg
- Coroutine
- EC2
- nestedfunction
- annotate
- Today
- Total
BackEnd King KY
TIL12 - AWS AI&ML 온라인 컨퍼런스 : ML 데이터 준비 및 WorkFlow 프로토타이핑 배워보기 본문
TIL12 - AWS AI&ML 온라인 컨퍼런스 : ML 데이터 준비 및 WorkFlow 프로토타이핑 배워보기
Django King, Lee 2022. 3. 1. 14:27
✔️Intro
2월 24일 AWS에서 하는 AI&ML 온라인 컨퍼런스가 있었습니다.
어떻게 보면 제가 백엔드 개발자가 된 것도, 그 중 파이썬을 배우게 된 것도 AI&ML의 영향이 커서 듣고 싶었는데, 그 때 업무 중이라 듣지 못 했습니다. AWS에서 감사하게도 다시보기를 제공해줘서 쉬는 날 보게 되었습니다. 다시보기는 3월 31일까지라고 합니다.
발표는 AWS에서 AI&ML 기술 지원을 담당하고 계신 문곤수님께서 해주셨습니다.
✔️Index
- 머신 러닝 개요 및 데이터 준비의 중요성
- CSV 포맷 데이터 준비 및 ML Workflow 프로토타이핑
- 이미지 데이터 준비 및 ML Workflow 프로토타이핑
✔️1. 머신러닝 개요 및 데이터 준비의 중요성

가장 일반적인 ML 프로세스입니다.
- 문제 정의 후 데이터 준비가 이루어집니다. 데이터 준비는 데이터 수집, 정제, 분석, 이해 및 정리 작업으로 보시면 됩니다.
- 알고리즘 및 프레임워크 설정 후 모델 훈련 코드를 작성합니다.
- 모델 훈련을 통해 튜닝을 한 후 배포를 합니다.
- 지속적인 모니터링을 통해 재학습 시킵니다.

데이터 준비에는 약 80%의 시간이 소요된다고 합니다. 데이터 준비는 ML 프로세스에서 말한 수집, 정제, 분석, 이해가 다 포함된 과정입니다.
데이터 준비가 왜 가장 중요할까요?
발표를 해주신 문곤수님께서 ML의 대가 중 한 분인 앤드류 응(Andrew Ng)의 말을 인용해서 설명해주셨습니다.
"많은 응용프로그램의 모델과 코드는 기본적으로 해결된 문제입니다. 이제 모델이 특정 지점까지 발전했으므로 데이터도 작동하도록 해야합니다" 라는 말인데, 이게 어떤 뜻이냐면 "이미 검증된 모델은 많으니 알고리즘 입력이 되는데 필요한 데이터에 더 집중을 해야 한다"라는 의미라고 합니다. 그래서 데이터 품질을 보장하는 것, 그것이 ML팀의 중요한 작업이라고 하며 위에서 언급한 앤드류 응 역시 모델 중심의 AI에서 데이터 중심의 AI로 변화하는 캠페인을 진행하고 있다고 합니다. 현업에서는 아직까진 모델 중심 AI로 개발되어 있는데, 모델 검증이 틀린 경우 데이터 정합성이 맞지 않아서 나오는 경우가 많다고 합니다.
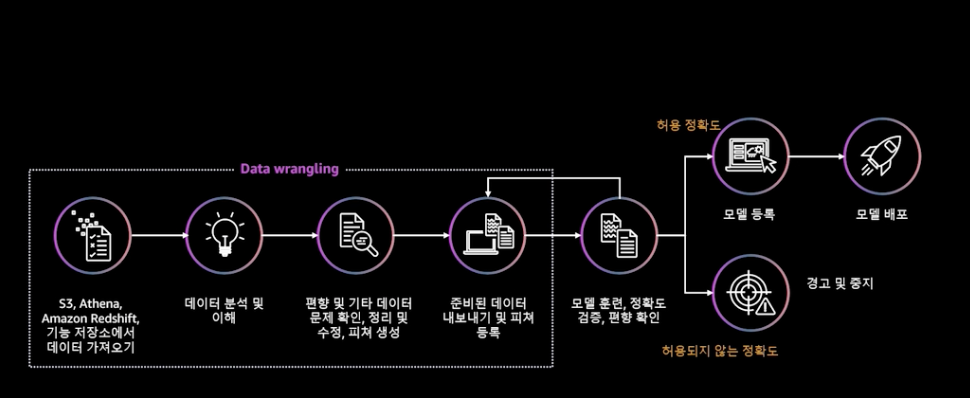
지금까지 문곤수님이 말씀 하신 Workflow를 이미지로 나타내면 다음과 같습니다.
데이터에 대한 작업이 우선으로 이루어 진 후, 모델에 대해 검증이 이루어집니다. 여기서 정확도에 따라 허용되지 않으면 사용하지 않고, 사용되면 배포합니다. 그리고 데이터가 정상범주를 벗어나는지 꾸준히 확인합니다. 그러면서 AWS ML Stack, Amazon SageMaker Notebooks 등에 대해 설명해주셨는데, 이 부분은 나중에 기회될 때 제가 사용해보면서 포스팅 하도록 하겠습니다.
✔️2. CSV 데이터 준비 및 프로토타이핑
CSV 데이터를 이용하여, 이동 통신 가입자의 고객이탈 유무를 분석하는 문제입니다. Pytorch나 Tensorflow를 사용해보지 않아 아마 코드를 작성하는 과정은 포스팅에서 생략할 것 같습니다.
자세한 과정과 데이터들은 해당 강의에서 적어준 URL을 들어가시면 알 수 있습니다.
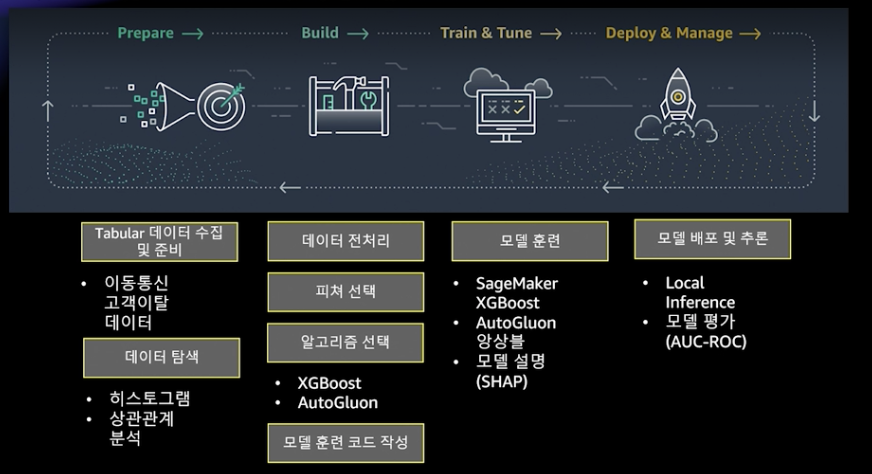
프로토타이핑의 개요입니다.
데이터에서 0은 고객유지, 1은 고객이탈 등 다양한 설명이 있습니다. 자세한 사항은 아까 작성한 URL에 나와 있습니다.
(강의 후 Repository Clone 후 실습을 진행하는데, 아직 기본적인 이해도가 없는 상태여서 진행하지 않았습니다.)
✔️3. 이미지 데이터 준비 및 ML Workflow 프로토타이핑
예시 코드는 같은 Repository에 있으며, 데이터는 업계에서 많이 사용하는 COCO와 CIFar10에서 가져왔다고 합니다. COCO에서 10개 카테고리의 데이터를 가져오고, CIFar10에서 1개의 카테고리를 가져온다고 합니다.
아래 프로토타이핑의 이미지인데, 프레임워크를 TesorFlow, Pytorch, SageMaker 중 하나를 선택하면 된다고 합니다.
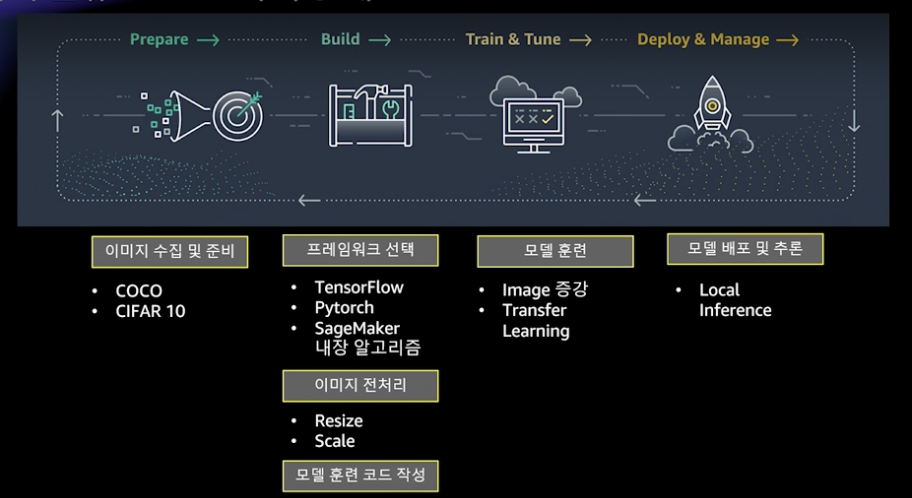
COCO와 CIFar10은 데이터 구조가 다르다고 합니다. COCO의 주석을 다운로드 하고 카테고리를 추출하는데, 여기서 주석이란 이미지의 메타 정보로서 이미지 이름, 경로, 카테고리, 바운딩 박스, 세그멘테이션 정보등이 있다고 합니다.
✔️마치며..
꿈만 있었지, 아는 건 없는 상태였습니다. 당연히 어려울 거라 생각했고, 어려운 길을 통해 갈 거라고 생각했기 때문에 나중에 해보면 재미있을 것 같았습니다. 데이터를 통해 분석하고 의사결정하는 게 재밌기 때문입니다.
그리고 마지막에 문곤수님께서 알려주신 AI&ML 리소스허브입니다.
열심히해서 언젠간 문곤수님께서 강의하시는 자리에 제가 앉아서 꼭 하고 싶습니다.

'AWS' 카테고리의 다른 글
| TIL42 - linux에서 redis permission denied 문제 해결 (0) | 2023.01.11 |
|---|---|
| TIL37 - Elastic Beanstalk에 Django 애플리케이션 배포 (1) (0) | 2022.11.19 |
| TIL36 - EC2에 Pull받기 (0) | 2022.11.13 |
| TIL33 - AWS EC2 인스턴스 생성 (0) | 2022.09.11 |
| TIL32 - AWS IAM을 이용한 사용자 권한 설정과 MFA 설정 (0) | 2022.09.11 |



