
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- database
- Continuous Deployment
- dry-yasg
- Prefetch_related
- testcase
- DjangoCache
- to_attr
- django
- docker
- Git
- racecondition
- Continuous Delivery
- 백준
- aggregate
- aws
- F객체
- apitestcase
- Python
- CI
- CD
- QuerySet
- DRF
- DjangoRestFramework
- Coroutine
- annotate
- 코루틴
- nestedfunction
- 도커
- EC2
- Transaction
- Today
- Total
BackEnd King KY
TIL14 - DB Indexing 본문

✔️What is Indexing?
위키백과에 따르면, 인덱싱이란 테이블에 대한 동작 속도를 높여주는 자료 구조를 일컫는 말입니다. 인덱스는 테이블 내의 1개의 컬럼 혹은 여러 개의 컬럼을 이용하여 생성될 수 있습니다. 고속 검색뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공합니다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작습니다. 왜냐하면 보통 인덱스는 키-필드만 갖고 잇고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문입니다.
그래서 인덱스로 지정된 컬럼에 대해 조회를 할 때 별도로 저장된 디스크에서 먼저 찾고 저장된 실제 테이블로 찾아갑니다. 말 그대로 목차 그 자체라고 볼 수 있습니다. 책에서 목차를 통해 원하는 페이지로 갈 수 있기 때문입니다. 그래서 필터링할 때 테이블 풀 스캔할 필요없이, 인덱스에 저장된 걸 가져오면 되기 때문에 동작 속도가 빠르다고 하는 것입니다.
그러면 인덱스가 동작속도를 높여준다는 것은 개념적으로 알았는데, Django에서는 어떻게 동작할까요? 직접 입력해보면서 알아보겠습니다. 출처는 공식문서입니다.
✔️Indexing in Django
Django에서 Index 클래스는 Database Index를 쉽게 생성하게 해줍니다. models.py에서 각 모델별로 특징을 설정하는 Class Meta에서 indexes라는 옵션을 통해 사용되며, django.db.models.indexes에 정의되어 있습니다. 인덱스 클래스에 대해 설명 후 적용할 예정이며, 천천히 이 내용에 대해 기술해보겠습니다.
✔️Index Options
Index클래스에 대핸 설명은 이렇게 되어 있으며, 각 파라미터별로 알아보겠습니다.
Class Index(*expressions, fields=(), name=None, db_tablespace=None, opclasses=(), condition=None, include=None)
✔️expressions
expressions는 Django 3.2 버전부터 새로 생겼습니다. expressions는 표현식 및 데이터베이스 기능에 대한 기능적 인덱스를 생성할 수 있습니다. 예를 들어 아래의 코드를 보면
Index(Lower('title').desc(), 'pub_date', name='lower_title_date_idx)인덱스를 생성하는데, title 컬럼의 소문자값의 내림차순으로 만들겠다는 의미이고, 그 다음으로 pub_date의 일반 정렬(오름차순)으로 만들겠다는 의미입니다. 그리고 이렇게 만들어진 인덱스의 이름이 lower_title_date_idx입니다.
다른 예를 들면,
Index(F('height')*F('weight'), Round('weight'), name='calc_idx')데이터베이스에 직접 접근하여 값을 가져오는 F객체의 특성을 이용하여 height와 weight의 곱을 인덱스로 만들고 weight는 반올림하겠다는 의미입니다.
그리고 name은 expressions를 이용할 때만 요구되어지는 파라미터입니다.
또한 Oracle, MySQL, MariaDB, PostgreSQL별로 제약사항이 있습니다. 저는 현재 PostgreSQL을 사용하기 때문에 PostgreSQL에 대해서만 제약사항을 작성해보자면 PostgreSQL은 인덱스에서 참조되는 함수와 연산자가 Immutable해야 합니다. Django에서는 검증하지 않지만 PostgreSQL에서 잡아낸다고 하며 Concat()과 같은 함수를 허용하지 않는다고 합니다. immutable의 의미는 수정불가능한을 의미합니다.
✔️fields
인덱스가 필요한 컬럼명을 리스트 또는 튜플로 담습니다. 기본값으로 Index는 내림차순으로 각 컬럼마다 생성됩니다. 하지만 어떤 컬럼은 내림차순, 어떤 컬럼은 오름차순으로 정렬이 필요할 때 사용하게 되는 것입니다.
예를 들어 아래 코드를 보면,
Index(fields=['headline', '-pub_date'])headline은 오름차순, pub_date는 내림차순으로 설정하게 되는 것입니다. 단, MySQL에서는 제공하지 않는 기능이며 앞에 -를 붙여도 오름차순으로 정렬되어 나온다고 합니다. 정렬이 왜 중요하냐면, Order by는 부하가 많이 걸리는 작업이기 때문입니다. 아무래도 대량의 데이터를 정렬하려니 그런 것인데, 인덱스를 통해 이미 정렬을 해놨다면 정렬되어있는 것만 가져오면 되기 때문에 작업 속도가 빨라지게 되는 것입니다.
✔️name
인덱스의 이름입니다. 다만 인덱스의 이름을 설정하지 않으면 Django에서는 자동으로 만들어준다고 합니다. 다른 데이터베이스와의 호환성을 위하여 인덱스의 이름은 30자를 초과할 수 없으며 숫자 또는 밑줄로 시작해서도 안된다고 합니다.
✔️tablespace
처음에 tablespace라는 걸 보고, Meta에서 선언하는 db_table과 같은 개념인 줄 알았는데 그건 아니었습니다. 쉽게 말해 테이블을 저장하는 공간인데 프로젝트를 할 때 마다 여러개의 테이블이 만들어질테고, 그 테이블이 저장될 공간이 필요할 것입니다. 그 공간을 tablespace라고 합니다. 어떻게보면 객체의 기본이 되는 실제 데이터를 보관할 수 있는 저장위치라고 할 수 있는 것입니다.
인덱스가 두 개 이상 설정되어 있어야 tablespace가 생성됩니다. 아래의 코드로 예를 들면
class TablespaceExample(models.Model):
name = models.CharField(max_length=30, db_index=True, db_tablespace="indexes")
data = models.CharField(max_length=255, db_index=True)
shortcut = models.CharField(max_length=7)
edges = models.ManyToManyField(to="self", db_tablespace="indexes")
class Meta:
db_tablespace = "tables"
indexes = [models.Index(fields=['shortcut'], db_tablespace='other_indexes')]name과 edges 필드에 대한 인덱스는 class Meta에서 선언된 indexes라는 테이블스페이스에 저장됩니다. 이렇게 해서 index를 만들수 있게 되는 것입니다. 컬럼을 만들 때. db_tablespace를 지정하지 않으면 자동으로 Meta에서 설정한 tablespace로 지정됩니다.
✔️opclasses
opclasses는 인덱스에 사용할 PostgreSQL의 연산자 클래스 이름입니다. 사용자 정의 연산자 클래스가 필요한 경우, 각 인덱스의 필드에 대해 하나씩 설정해야 하는데, 이 부분은 PostgreSQL에만 적용될 내용이므로 넘어가겠습니다.
✔️condition
테이블이 매우 크거나 쿼리가 많을 경우, 유용한 condition 입니다. Django의 Q객체를 이용하여 더 구체화할 수 있습니다.
예를 들어 condition=Q(pages__gte=400) 이라고 선언하면 pages가 400이상인 것만 조건으로 걸어서 인덱싱을 한다는 뜻이됩니다. PostgreSQL, SQLite, Oracle, MySQL, MariaDB에 대해 제약사항이 있는데 PostgreSQL에 대해서만 간단하게 써보겠습니다.
PostgreSQL은 조건에서 참조되는 함수가 immutable해야 합니다. 예를 들어 datetime은 immutable하고 DateTimeField는 immutable하지 않다는 반대의 특징을 가지고 있습니다. 그러면 DateTimeField에 대해 인덱싱을 하려고 할 때 tzinfo라는 값까지 함께 제공해야 합니다. tzinfo는 datetime 및 time 클래스에서 시간 조정에 대한 커스터마이징 기능을 제공하기 때문에 DateTimeField를 인덱싱할 수 있게 도와주기 때문입니다.
✔️Include
include를 선언하면, 그 필드만 선택하고 인덱싱 필드로만 필터링하는 쿼리에 인덱싱 전용 스캔을 사용할 수 있으며 컬럼명을 리스트 혹은 튜플로 나타내야 합니다. 말이 어려우니 코드로 예시를 들어보겠습니다.
Index(name='covering_index', fields=['headline'], include=['pub_date'])이렇게 되면 인덱스에서 데이터를 가져오는 동안 headline에서 필터링하고 pub_date도 선택할 수 있습니다. 쉽게 말해 인덱스안의 작은 인덱스를 하나 더 설정할 수 있게 됩니다. 다만, 정렬이나 필터링은 할 수 없습니다. 정렬 및 필터링이 headline으로는 가능하나 pub_date로는 안된다는 의미입니다.
✔️과연 얼마나 유의미한 차이가 날까?
우선 저는 아래와 같이 모델을 만들고 100만개의 데이터를 넣었습니다. 그리고 데이터의 정확성을 위해 first_name과 last_name 모두 같은 값을 넣었습니다. first_name이 ky면 last_name도 ky가 되는 형식의 데이터들입니다. 그리고 first_name에만 index 설정을 했습니다.
from django.db import models
class Customer(models.Model):
first_name = models.CharField(max_length=20)
last_name = models.CharField(max_length=20)
class Meta:
indexes = [
models.Index(fields=['first_name'], name='first_name_idx'),
]이 때, first_name과 last_name에서 대소문자 구분없이 a가 들어가는 거의 개수를 구해보겠습니다.
class IndexFirstNameView(View):
def get(self, request, *args, **kwargs):
c = Customer.objects.filter(first_name__icontains="a")
d = Customer.objects.filter(last_name__icontains="a")
return JsonResponse({"count":c.count()}, status=200)그래서 첫 번째로 first_name에 a가 들어간 거의 개수를 구해보고, 그 다음 last_name에 a가 들어간 것의 개수를 구해보며 응답속도를 측정해보겠습니다. 첫 번째 사진이 c의 개수, 두 번째 사진이 d의 개수를 구할 때의 응답속도가 나오는 이미지입니다.
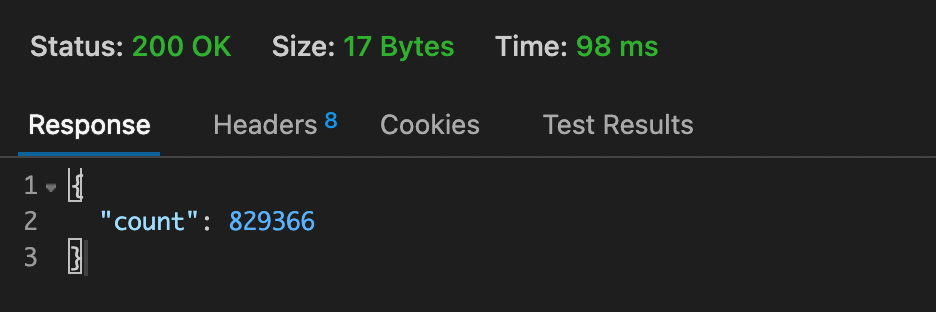
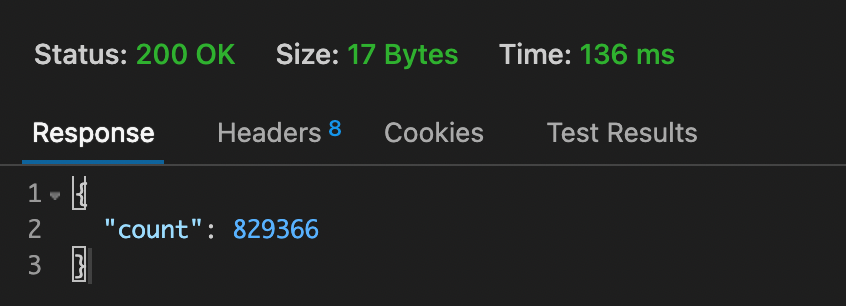
첫 번째 이미지를 보시면 인덱스를 설정한 first_name의 개수를 구하는 Time은 98ms가 나오며 계속 요청을 보낸 결과 대략 80~90을 왔다갔다 하는 결과가 나왔습니다. 그리고 인덱스가 설정되지 않은 last_name의 개수를 구하는 Time은 136ms가 나오며 130~140을 왔다갔다 합니다. 인덱싱을 통해 이렇게 유의미한 결과를 나타낼 수 있었습니다.
다만, 항상 Indexing이 능사는 아닙니다. 필요한 상황이 있을터이니 그 때 알맞게 설정해보는 걸 권장드립니다. 왜냐하면 정렬이 유지되어 있어야 하는데, 값이 자주 바뀌는 경우 인덱스로 지정한 테이블스페이스와 실제 테이블 모두 수정 작업이 필요하며, 인덱스 역시 데이터베이스 공간을 갉아먹기 때문에 너무 많은 선언은 좋지 않기 때문입니다.
'Database' 카테고리의 다른 글
| TIL43 - alembic에서 metadata를 왜 설정해야 할까 (0) | 2023.02.04 |
|---|---|
| TIL8 - Transaction(2/2) (0) | 2022.02.24 |
| TIL8 - Transaction(1/2) (0) | 2022.02.23 |


